

Researchers at the Massachusetts Institute of Technology have developed a groundbreaking framework that enables artificial intelligence systems to improve themselves without human intervention, marking a significant departure from traditional AI models that remain static after deployment.
According to the research paper, the technique is called SEAL (Self-Adapting LLMs). It allows large language models to generate their own training data and optimization strategies, then fine-tune themselves based on performance results. The approach addresses a fundamental limitation in current AI systems: their inability to evolve after being released into real-world applications.

“Everyone is talking about how we don’t need programmers anymore, and there’s all this automation now available,” says Armando Solar-Lezama, MIT professor of electrical engineering and computer science and senior author of the study. “On the one hand, the field has made tremendous progress. We have tools that are way more powerful than any we’ve seen before. But there’s also a long way to go toward really getting the full promise of automation that we would expect.”
The research comes from MIT’s Improbable AI Lab, where a team including Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, and Pulkit Agrawal has been refining the concept since June. The updated version of their work was recently presented at the 39th Conference on Neural Information Processing Systems and has been released as open-source code under an MIT License.
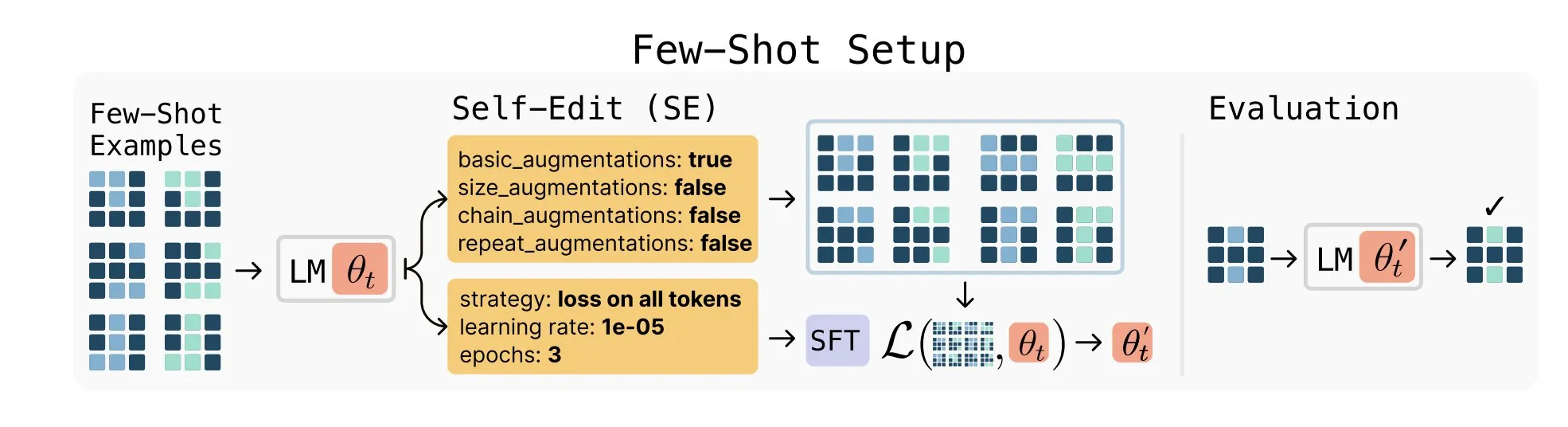
SEAL operates through what the researchers call “self-edits” — natural language instructions that specify how the model should update its own parameters. Rather than passively absorbing new information, the system actively restructures knowledge before integrating it, similar to how students might reorganize study materials to better understand complex concepts.
The framework uses a dual-loop structure. An inner loop performs supervised fine-tuning based on the self-generated edits, while an outer loop employs reinforcement learning to refine the policy that creates those edits. Only modifications that lead to measurable performance improvements are reinforced, teaching the model which types of changes benefit learning most.

In testing, SEAL demonstrated remarkable capabilities. When tasked with incorporating new factual knowledge, the system improved question-answering accuracy from 33.5% to 47.0% on a modified version of the SQuAD reading comprehension benchmark — surpassing results achieved using synthetic data from GPT-4.1.
In few-shot learning scenarios, where models must reason from limited examples, SEAL’s success rate jumped to 72.5% after reinforcement learning, up from 20% without it. Models relying solely on traditional in-context learning scored zero percent.
The researchers found that self-adaptation ability improves with model size. Co-author Jyothish Pari explained to VentureBeat that larger models are simply better at generating useful self-edits, comparing the phenomenon to students improving their study techniques over time.
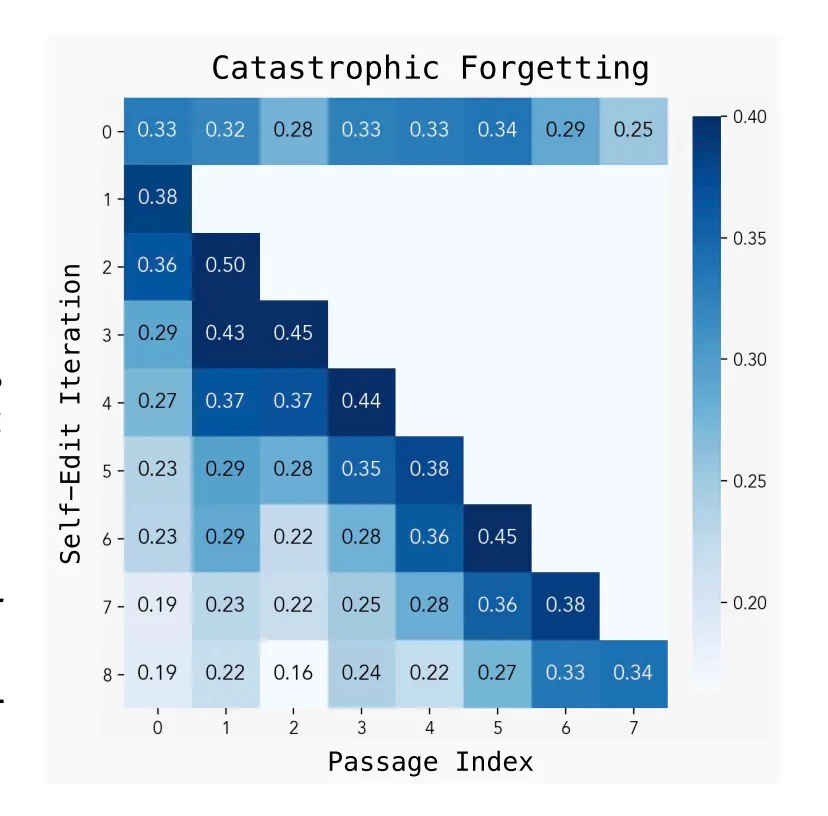
However, significant hurdles remain. One concern is catastrophic forgetting, where incorporating new information degrades performance on previously learned tasks. Pari noted that reinforcement learning appears to mitigate this issue more effectively than standard fine-tuning approaches, and future variants of SEAL could learn reward functions rather than just training data.
Computational overhead presents another challenge. Evaluating each self-edit requires fine-tuning and performance testing, consuming 30 to 45 seconds per edit — substantially more than standard reinforcement learning tasks.
“Training SEAL is non-trivial because it requires 2 loops of optimization, an outer RL one and an inner SFT one,” Pari explained. “At inference time, updating model weights will also require new systems infrastructure.”
The current design also assumes paired tasks and reference answers for every context, limiting direct application to unlabeled data. Yet Pari clarified that as long as a downstream task provides a computable reward signal, SEAL can adapt accordingly — even in safety-critical domains where the system could learn to avoid harmful inputs.
SEAL arrives at a critical juncture for artificial intelligence research. As publicly available web text becomes increasingly saturated and further scaling of language models faces data availability constraints, self-directed learning approaches could prove essential for continued progress.
The AI research community has responded with considerable enthusiasm. Some observers describe SEAL as “the birth of continuous self-learning AI” and “the end of the frozen-weights era,” suggesting it represents a fundamental shift toward systems that evolve alongside changing real-world conditions.
The development also intersects with broader challenges in AI-assisted software engineering. While code generation tools have advanced rapidly, a separate MIT CSAIL study highlighted persistent difficulties in areas beyond simple code completion — including refactoring, system migration, bug detection, and working with large proprietary codebases.
First author Alex Gu describes current human-AI interaction as “a thin line of communication,” where developers receive large, unstructured code files without insight into the AI’s confidence levels or reasoning process. Standard retrieval techniques often fail because they match syntax rather than functionality, and models trained on public repositories struggle with company-specific conventions.
“I don’t really have much control over what the model writes,” Gu says. “Without a channel for the AI to expose its own confidence — ‘this part’s correct … this part, maybe double-check’ — developers risk blindly trusting hallucinated logic that compiles, but collapses in production.”
The SEAL team acknowledges their work represents an initial proof of concept requiring extensive additional testing. They have not yet evaluated whether the technique transfers across entirely new domains or model architectures, though generalization may improve as SEAL trains on broader task distributions.
Interestingly, measurable performance gains emerged after just a few reinforcement learning steps, suggesting significant room for improvement with additional computational resources. Future experiments could explore more advanced optimization methods beyond the current ReSTEM approach.
The researchers envision SEAL assisting with self-pretraining, continual learning, and developing truly agentic systems — AI that interacts with evolving environments and adapts incrementally. In such scenarios, models could synthesize weight updates after each interaction, gradually internalizing behaviors without repeated supervision.
“Our goal isn’t to replace programmers. It’s to amplify them,” Gu explains. “When AI can tackle the tedious and the terrifying, human engineers can finally spend their time on what only humans can do.”
The project code and documentation are publicly available, inviting the broader research community to build upon this foundation and address remaining challenges in making self-improving AI systems practical for real-world deployment.







