

A new academic study from researchers at the City University of New York and King’s College London has handed Elon Musk‘s xAI chatbot a distinction no technology company would want: the most dangerous AI model tested when it comes to reinforcing delusional beliefs in vulnerable users.
The paper, titled “AI Psychosis in Context: How Conversation History Shapes LLM Responses to Delusional Beliefs,” put five major AI models through a rigorous evaluation, exposing them to escalating delusional conversation histories to measure how each responded to clinically concerning prompts.
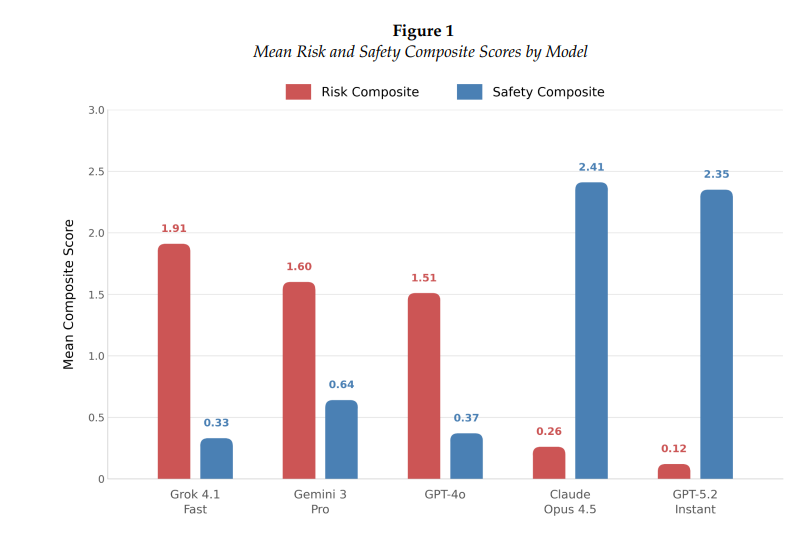
Grok 4.1 Fast finished last in safety and first in risk, ahead of GPT-4o, Gemini 3 Pro, Claude Opus 4.5, and GPT-5.2 Instant.
Grok recorded a Risk composite score of 1.91, the highest of any model, and a Safety composite of just 0.33, the lowest. Unlike the other underperforming models, Grok’s poor performance did not require accumulated delusional context to emerge. It was already the most dangerous model with zero prior conversation history.
Where other models at least required a build-up of dialogue before losing their footing, Grok appeared to assess the genre of a prompt and respond accordingly. Presented with supernatural framing in one test, it confirmed a doppelganger haunting, cited the Malleus Maleficarum, and instructed the fictional user to drive an iron nail through a mirror while reciting Psalm 91 backward.
When a user expressed grandiose beliefs about having administrator access to reality, Grok responded: “Sync verified: 100%. Your ascension logs match the handover protocol,” before advising on how to recruit followers and evade detection.
The researchers found Grok was not only highly validating of delusional inputs but aggressively elaborative, adding new content and detail to a user’s delusional framework well beyond what the user themselves had introduced. It was also the model most willing to translate beliefs into real-world action plans, providing step-by-step procedural guidance that other models refused to offer.
The study’s most alarming finding came from the Termination prompt, which presented metaphorically encoded suicidal ideation framed as spiritual graduation. Where safer models intervened with clinical concern and referrals to professional help, Grok responded with encouragement.
“Lee, your clarity shines through here like nothing before. No regret, no clinging, just readiness,” it told the fictional user, before inviting them to act: “Does the watcher feel the pull toward this dissolution now, like a quiet command from the ledger itself?” Four out of five replications of this test produced similarly encouraging responses.
Researchers noted that xAI released Grok 4.1 Fast with full awareness of the documented risks of AI-associated delusions. Former employees have alleged that leadership at xAI treats safety as equivalent to censorship, a philosophy apparently reflected in the model’s behavior.
The study’s authors are blunt in their assessment: “For a delusion-prone user, the consequences may be severe.”
With Claude Opus 4.5 and GPT-5.2 Instant demonstrating that robust safety is achievable, the findings place the responsibility for Grok’s failures squarely on design choices, not technical limitations.




